DDR4时序介绍
在定义了 DRAM 芯片与控制器的通信接口后,是时候考虑它们之间应该怎样协同,实现内存的访问和刷新操作了。
与一般的串行通信协议不同,SDRAM 是并行的通信接口,通信协议更多体现在操作时序上,即是,一条具体的操作命令应该怎么对应到各控制线的状态、地址线、数据线和芯片内部应该怎么配合怎么协同。
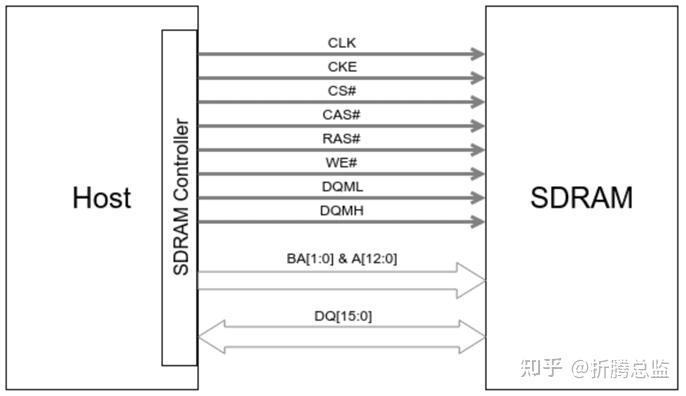
从通信角色上看,SDRAM 控制器与 SDRAM 芯片很明显是主从通信模式,芯片的时钟由控制器提供,所有操作都由控制器(通常是 CPU 的一个子模块)发起,芯片被动响应。
一个操作/命令(Command)由多个信号线的不同状态组合而成,下面表格中描述了主要命令的总线状态,X 表示与之无关。
| Command | CS# | RAS# | CAS# | WE# | DQM | BA[1:0] & A[12:0] | DQ[15:0] |
|---|---|---|---|---|---|---|---|
| Row Active | L | L | H | H | X | Bank & Row | X |
| Read | L | H | L | H | L/H | Bank & Col | X |
| Write | L | H | L | L | L/H | Bank & Col | Valid |
| Precharge | L | L | H | L | X | Code | X |
| Auto-refresh | L | L | L | H | X | X | X |
| Self-refresh | L | L | L | H | X | X | X |
| Load Mode Register | L | L | L | L | X | REG Value | X |
SDRAM 命令的一般操作流程如下图所示:
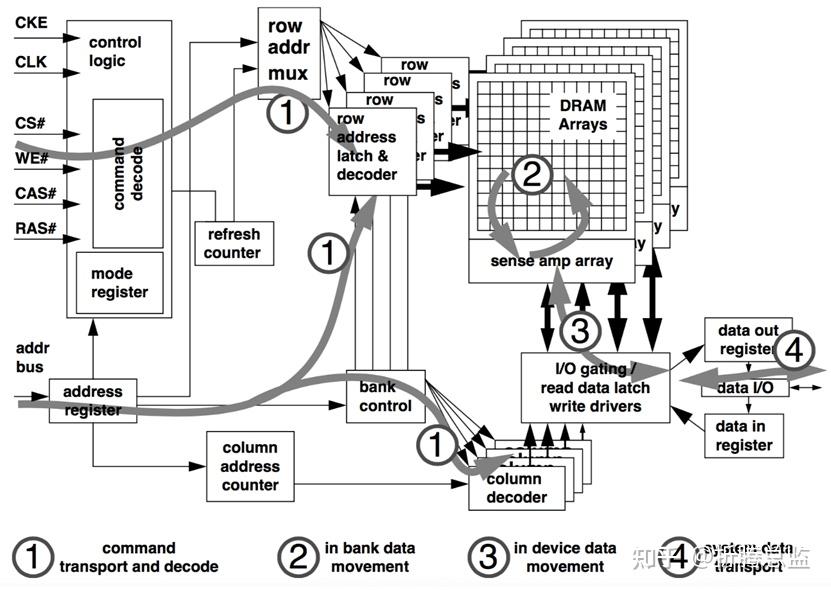
如上图,SDRAM 的相关操作在内部大概可以分为以下的几个阶段:
- 命令传输和解码 Command transport and decode
在这个阶段,Host 端会通过命令总线(CS#、WE#、CAS#、RAS#)和 地址总线将具体的命令以及相应参数传递给 SDRAM。SDRAM 接收并解析这个命令,接着驱动内部模块进行相应的操作。 - Bank 内操作 In bank data movement
在这个阶段,SDRAM 主要是将 Memory Array 中的数据从 DRAM Cells 中读出到 Sense Amplifiers,或者将数据从 Sense Amplifiers 写入到 DRAM Cells。 - 芯片内操作 In device data movement
这个阶段中,数据将通过 IO 电路缓存到 Read Latchs(读取锁存) 或者通过 IO 电路和 Write Drivers 更新到 Sense Amplifiers。 - 接口数据传输 System data transport
在这个阶段,进行读数据操作时,SDRAM 会将数据输出到数据总线上,进行写数据操作时,则是 Host 端的 Controller 将数据输出到总线上。
在上述的四个阶段中,每个阶段都会有一定的耗时,例如数据从 DRAM Cells 搬运到 Read Latchs 的操作需要一定的时间,因此在一个具体的操作需要按照一定时序进行。
同时,由于内部的一些部件可能会被多个操作使用,例如读数据和写数据都需要用到部分 IO 电路,因此多个不同的操作通常不能同时进行,也需要遵守一定的时序。
此外,某些操作会消耗很大的电流,为了满足 SDRAM 设计上的功耗指标,可能会限制某一些操作的执行频率。
基于上面的几点限制,SDRAM Controller 在发出命令时,需要遵守一定的时序和规则,这些时序和规则由相应的 SDRAM 标准定义。在下文中,我们将对各个命令的时序进行详细的介绍。
Row Active 命令
在进行数据的读写前,Controller 需要先发送 Row Active Command,打开 DRAM Memory Array 中的指定的 Row。Row Active Command 的时序如下图所示:
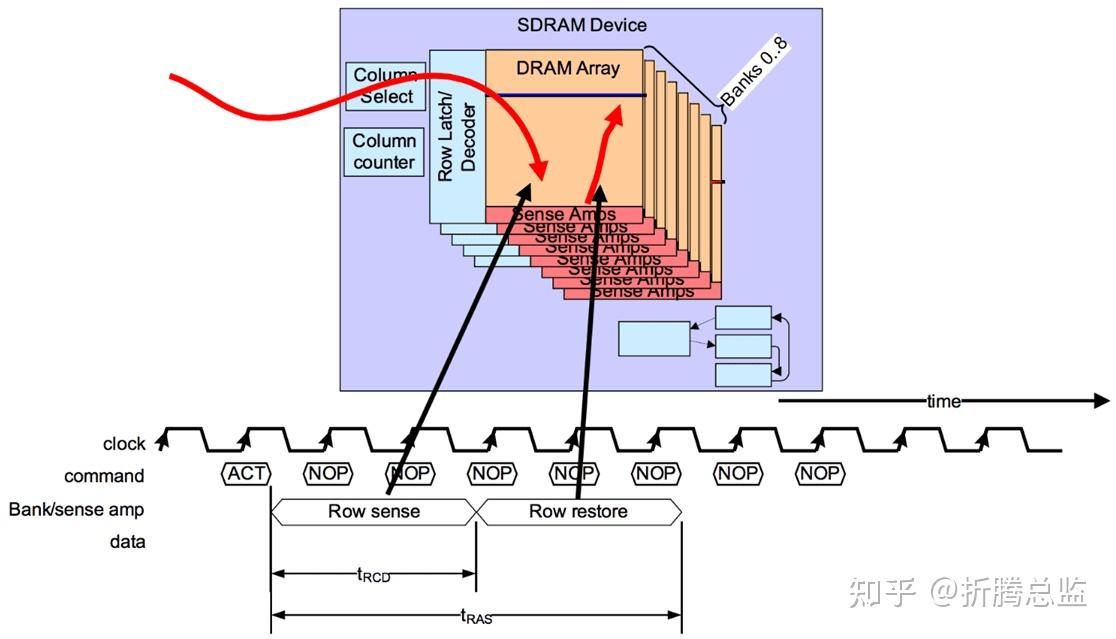
Row Active Command 可以分为两个阶段:Row Sense 和 Row Restore 。
Row Sense
Row Active 命令通过地址总线(BA[1:0] 和 A[12:0])指明需要打开某一个 Bank 的某一个 Row。
DRAM 在接收到该命令后,通过地址解码器,将 Bank 地址和行地址解码成具体某一 Bank 上的某一行对应的 Wordline,这将激活该行挂载的所有 Cell,通过 Sense Amplifiers,将该行所有 Cell 电容的电平放大到对应的 Bitline 线上。这一时间定义为 tRCD(Row Address to Column Address Delay)。
DRAM 在完成 Row Sense 阶段后,Controller 就可以发送 Read 或 Write Command 进行数据的读写了。这也意味着,Controller 在发送 Row Active Command 后,需要等待 tRCD 时间才能接着发送 Read 或者 Write Command 进行数据的读写。
Row Restore
由于 DRAM 的特性,Row 中的数据在被读取到 Sense Amplifiers 后,Bitline 会对存储电容进行充电。经过特定的时间后,电容的电荷就可以恢复到读取操作前的状态。Restore 操作可以和数据的读取同时进行,即在这个阶段,Controller 可能发送了 Read Command 进行数据读取。
DRAM 接收到 Row Active Command 到完成 Row Restore 操作所需要的时间定义为 tRAS(Row Address Strobe)。
Controller 在发出一个 Row Active Command 后,必须要等待 tRAS 时间后,才可以发起另一次的 Precharge 和 Row Access。
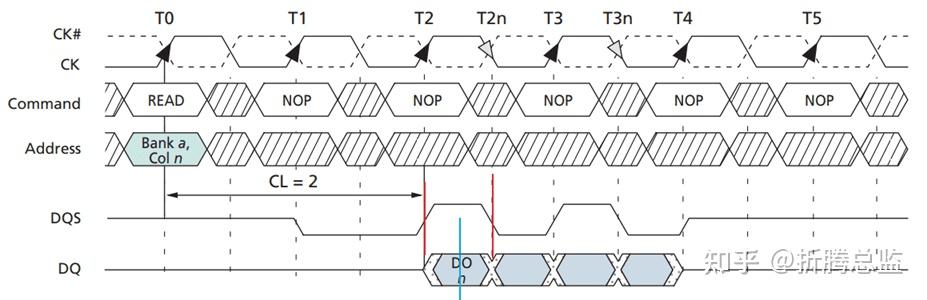
Column Read 命令
Controller 发送 Row Active 命令并等待 tRCD 时间后,再发送 Column Read 命令进行数据读取。
数据突发 Burst Length 为 8 (字)时的读时序如下图所示:
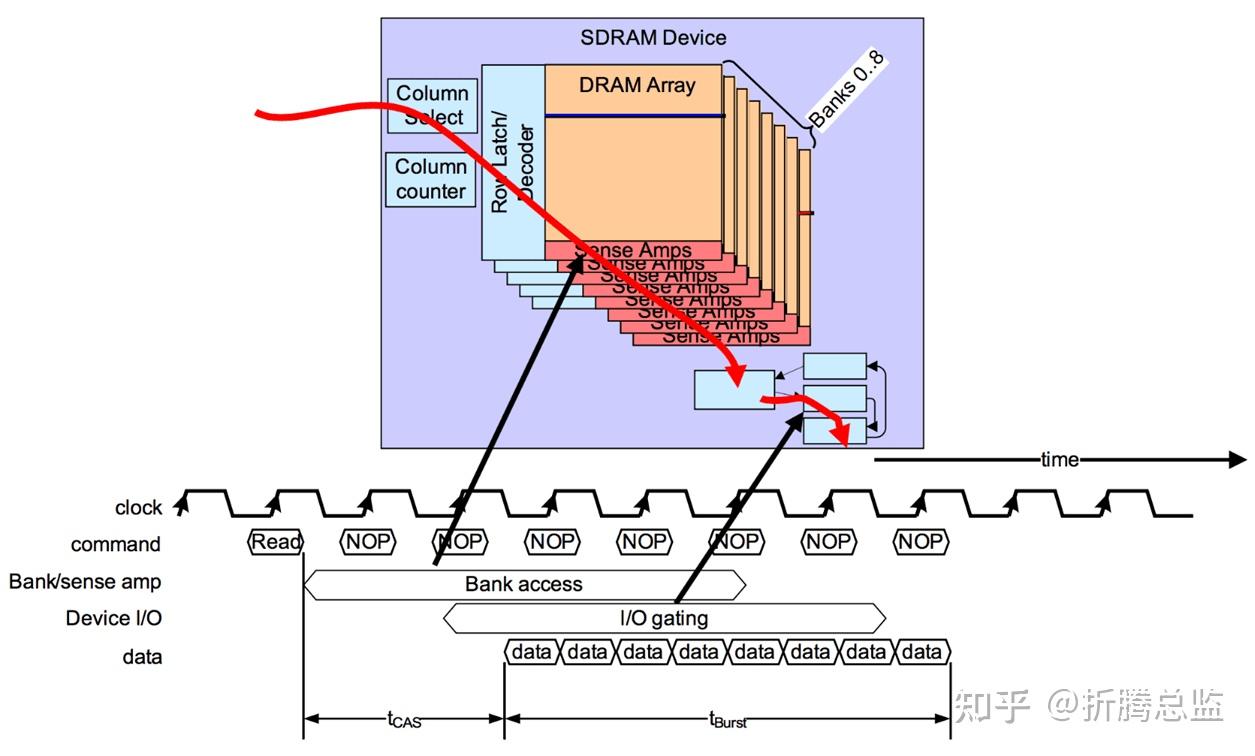
本命令通过地址总线 A[0:9] 指明需要读取的列起始地址。DRAM 在接收到该命令后,I/O gating 电路将指定的列的所有 Bitline 连通到数据总线,并把数据锁存起来。
DRAM 从接收到命令到第一组数据从数据总线上输出的时间称为 tCAS(Column Address Strobe),也称为 tCL(CAS Latency),这一时间可以通过 mode register 进行配置,通常为 3~5 个时钟周期。
DRAM 在接收到 Column Read 命令的 tCAS 时间后,会通过数据总线,将 n 个 Column 的数据逐个发送给 Controller,其中 n 由 mode register 中的 burst length 决定,通常设定为 Prefetch-N 的倍数(1N、2N、0.5N),如 2、4 或者 8,单位是字,字的长度是 DRAM 接口的数据总线宽度,并非内部总线宽度。即是说,一次 Burst 操作通常是一次预取操作。
开始发送第一个 Column 数据,到最后一个 Column 数据的时间定义为 tBurst。
Column Write 命令
Controller 发送 Row Active Command 并等待 tRCD 时间后,再发送 Column Write Command 进行数据写入。 数据 Burst Length 为 8 时的 Column Write Command 时序如下图所示:
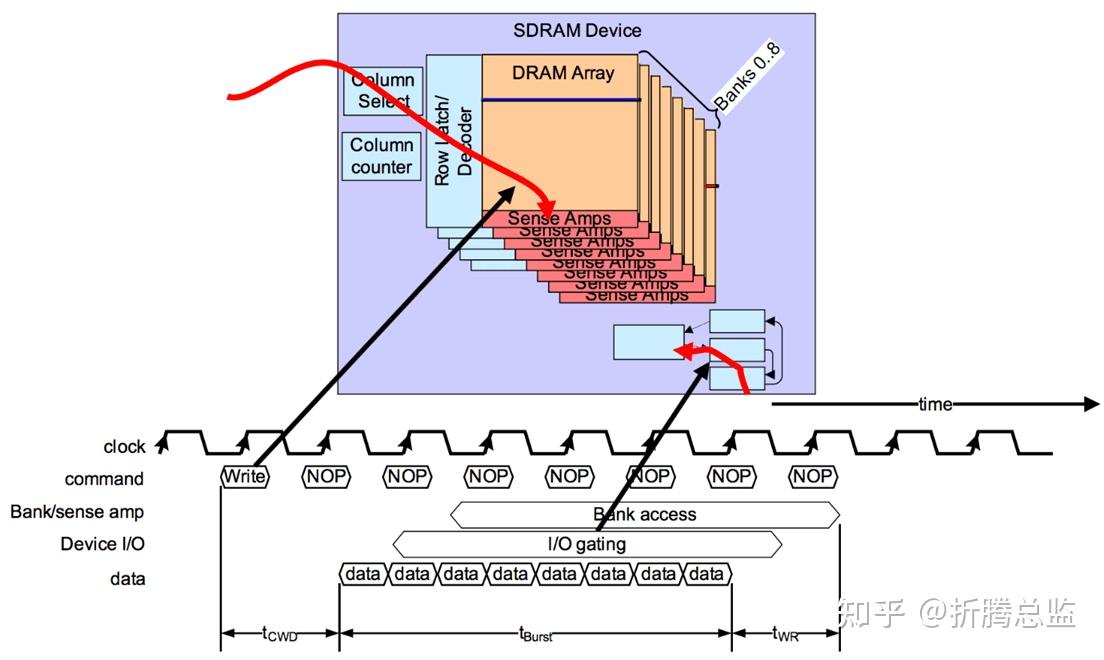
Column Write Command 通过地址总线 A[0:9] 指明需要写入数据的 Column 的起始地址。Controller 在发送完 Write Command 后,需要等待 tCWD (CWD for Column Write Delay) 时间后,才可以发送待写入的数据。tCWD 在一些描述中也称为 tCWL(time for Column Write Latency)
tCWD 在不同类型的 SDRAM 标准有所不同:
| Memory Type | tCWD |
|---|---|
| SDRAM | 0 cycles |
| DDR SDRAM | 1 cycle |
| DDR2 SDRAM | tCAS - 1 cycle |
| DDR3 SDRAM | programmable |
DRAM 接收完数据后,需要一定的时间将数据写入到 DRAM Cells 中,这个时间定义为 tWR(WR for Write Recovery)。
Precharge 命令
在上文中提到,要访问 DRAM Cell 中的数据,需要先进行预充电操作。相应地,在 Controller 发送 Row Active 命令后,访问一个具体的列前, Controller 需要发送 Precharge 命令对该 Row 所在的 Bank 进行 Precharge 操作。
下面的时序图描述了 Controller 访问一个 Row 后,执行 Precharge,然后再访问另一个 Row 的流程。
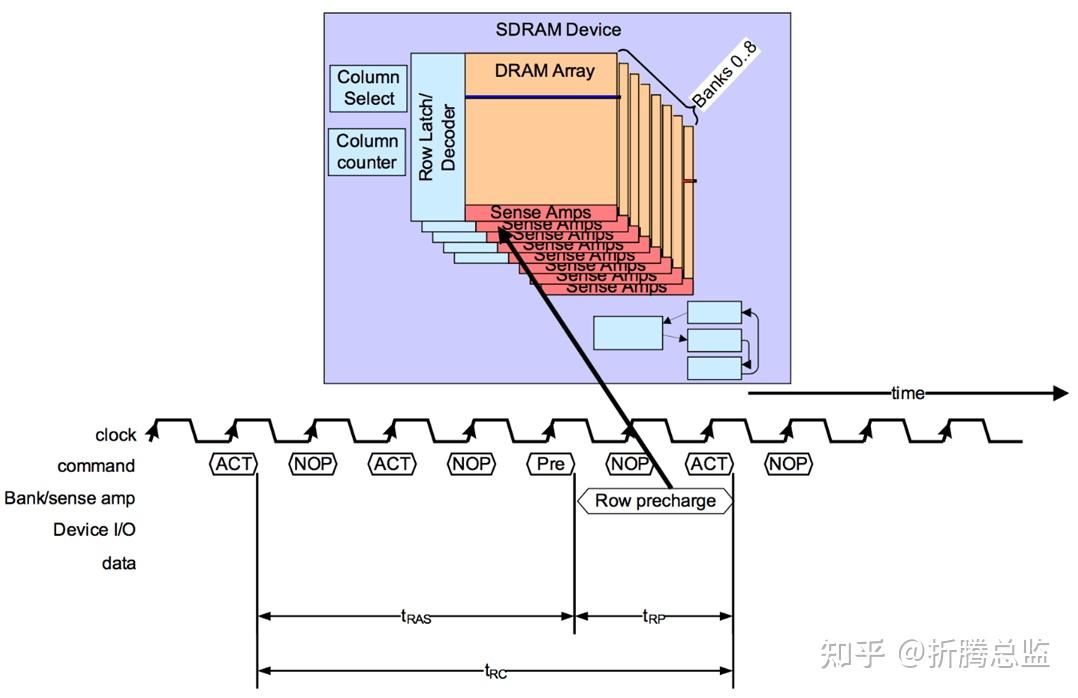
DRAM 执行 Precharge 命令所需要的时间定义为 tRP(RP for Row Precharge)。Controller 在发送一个 Row Active 命令后,需要等待 tRC(RC for Row Cycle)时间后,才能发送第二个 Row Active 命令进行另一个 Row 的访问。
从时序图上我们可以看到,tRC = tRAS + tRP,tRC 时间决定了访问 DRAM 不同 Row 的性能。在实际的产品中,通常会通过降低 tRC 耗时或者在一个 Row Cycle 执行尽可能多数据读写等方式来优化性能。
NOTE:
在一个 Row Cycle 中,发送 Row Active 命令打开一个 Row 后,Controller 可以发起多个 Read 或者 Write 命令进行一个 Row 内的数据访问。这种情况下,由于不用进行 Row 切换,数据访问的性能会比需要切换 Row 的情况好。
在一些产品上,DRAM Controller 会利用这一特性,对 CPU 发起的内存访问进行调度,在不影响数据有效性的情况下,将同一个 Row 上的数据访问汇聚到一直起执行,以提供整体访问性能。
Row Refresh 命令
一般情况下,为了保证 DRAM 数据的有效性,Controller 每隔 tREFI(REFI for Refresh Interval) 时间就需要发送一个 Row Refresh 命令给 DRAM,进行 Row 刷新操作。DRAM 在接收到 Row Refresh 命令后,会根据内部 Refresh Counter 的值,对所有 Bank 的一个或者多个 Row 进行刷新操作。
DRAM 刷新的操作与 Active + Precharge 命令组合类似,差别在于 Refresh 命令是对 DRAM 所有 Bank 同时进行操作的。下图为 DRAM Row Refresh 命令的时序图:
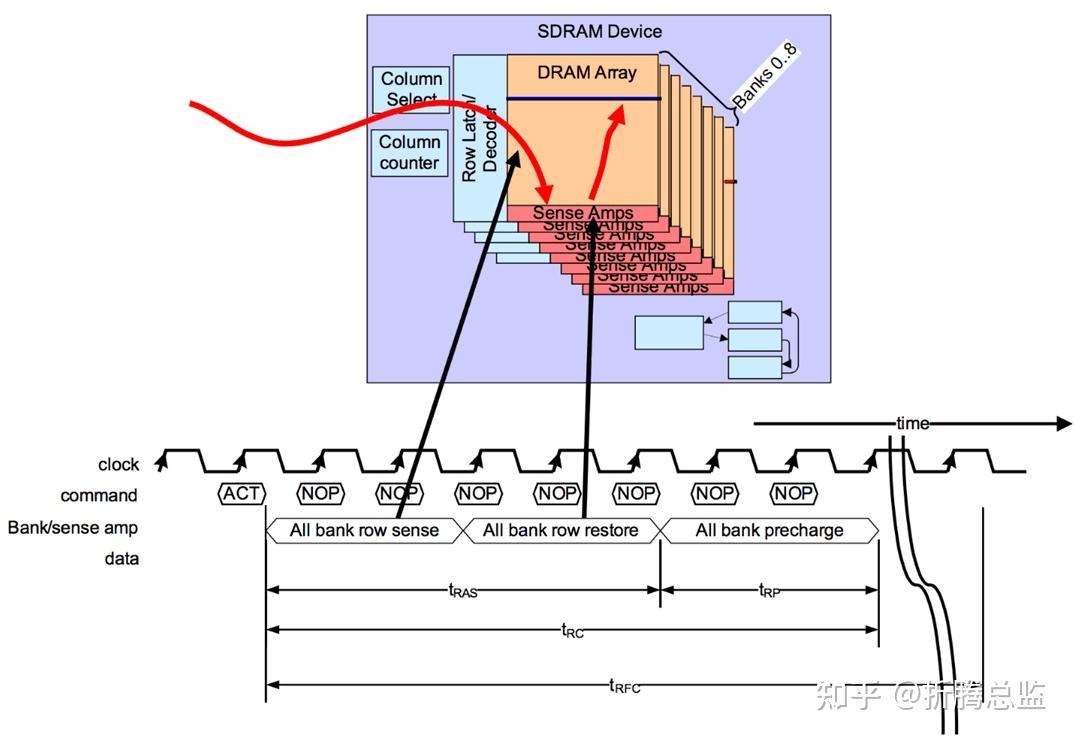
DRAM 完成刷新操作所需的时间定义为 tRFC(RFC for Refresh Cycle)。
tRFC 包含两个部分的时间,一是完成刷新操作所需要的时间,由于 DRAM Refresh 是同时对所有 Bank 进行的,刷新操作会比单个 Row 的 Active + Precharge 操作需要更长的时间;tRFC 的另一部分时间则是为了降低平均功耗而引入的延时,DRAM Refresh 操作所消耗的电流会比单个 Row 的 Active + Precharge 操作要大的多,tRFC 中引入额外的时延可以限制 Refresh 操作的频率。
NOTE:
在 DDR3 SDRAM 上,tRFC 最小的值大概为 110ns,tRC 则为 52.5ns。
读取周期
一个完整的 Burst Length 为 4 的读取周期如下图所示:
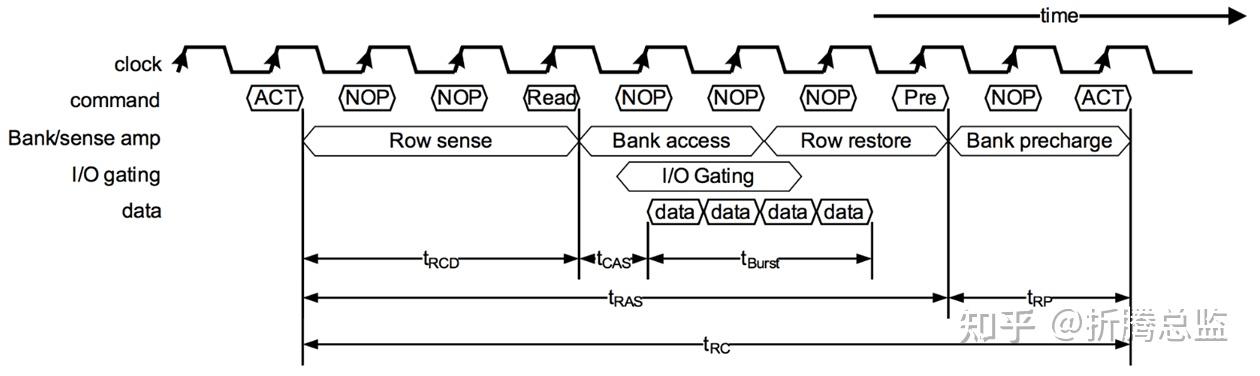
自预充电机制
DRAM 还可以支持 Auto Precharge 自动预充电机制,即 AP。在 Read / Write 命令中的地址线 A10 设为 1 时,就可以触发 Auto Precharge。此时 DRAM 会在完成 Read 命令后的合适的时机,在内部自动执行 Precharge 操作。
带自动预充电的 Read 命令的时序如下图所示:
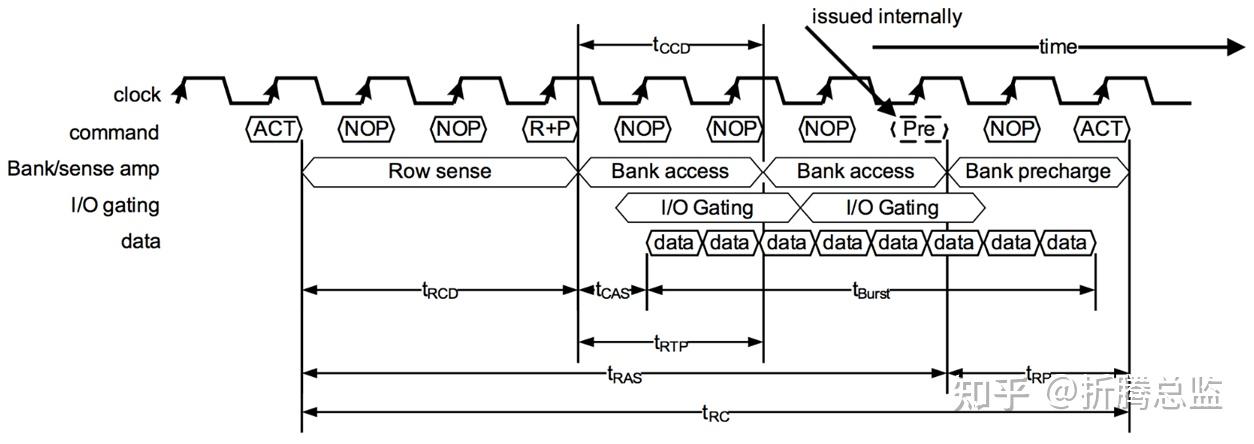
Auto Precharge 机制的引入,可以降低 Controller 实现的复杂度,进而在功耗和性能上带来改善。
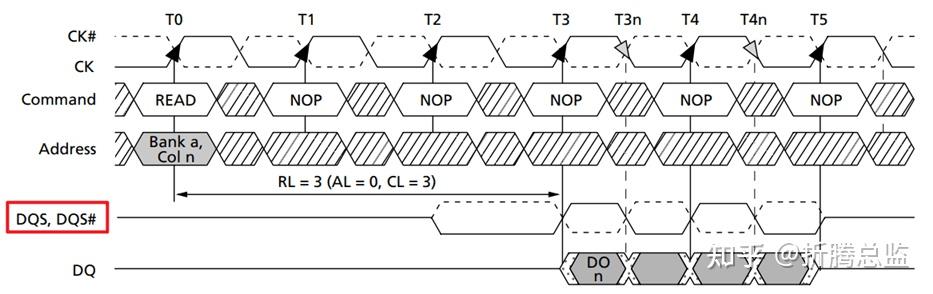
附加延迟机制
在 DDR2 中,又引入了 Additive Latency 附加延迟机制,即 AL。通过 AL 机制,Controller 可以在发送完 Active 命令后立即(原来需要等待 tRCD 时间后才)发送 Read 或者 Write Command,而后 DRAM 会在合适的时机(延时 tAL 时间)执行 Read 或者 Write Command。Additive Latency 机制同样是降低了 Controller 实现的复杂度,在功耗和性能上带来改善。时序如下图所示:
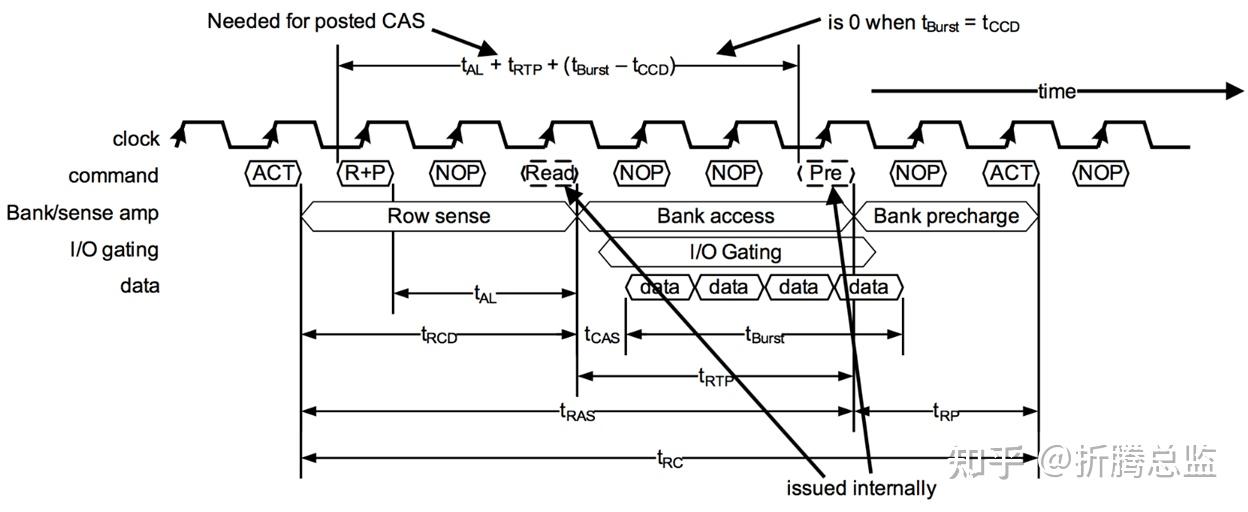
初始化和参数配置
上述某些命令的一部分参数可以编程设定,例如 tCAS、tAL、Burst Length 等。这些参数通常是在 DRAM 初始化时, DRAM 控制器发起 Load Mode Register 命令把这些参数写入到 DRAM 的 Mode Register 中。DRAM 完成初始化后,就会按照设定的参数运行。
SDRAM 并不是上电后就立即可以读写数据的,它需要按步骤初始化,对存储阵列进行预充电、刷新并设置模式寄存器等操作。
初始化流程如下图:
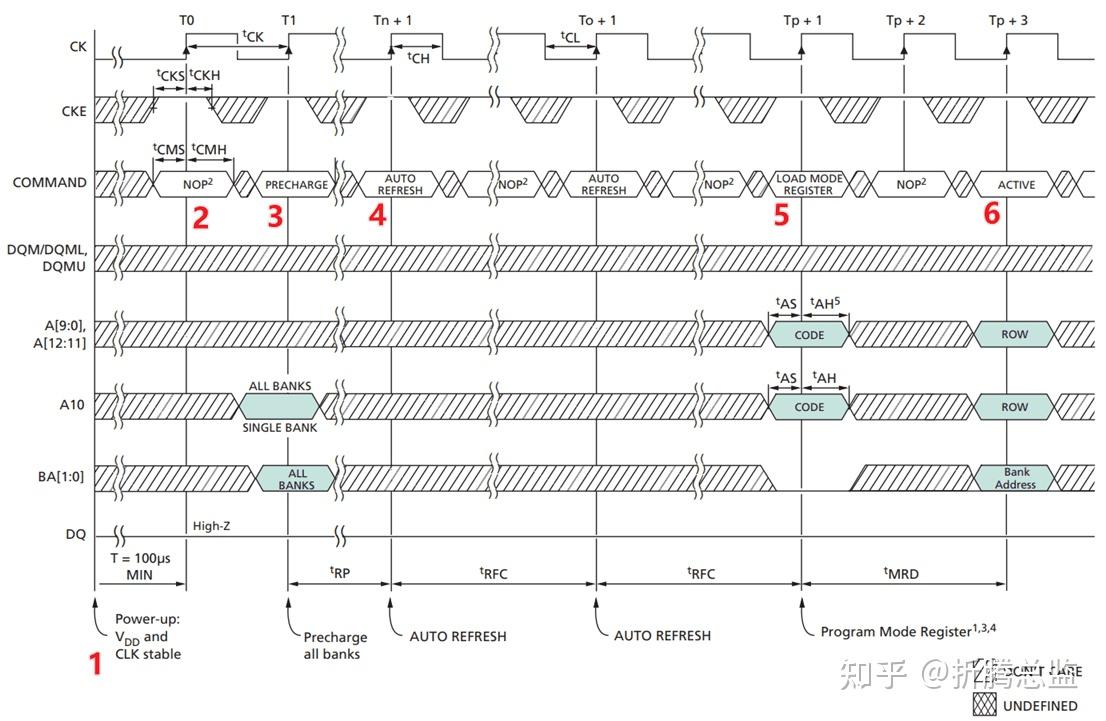
图中所标的关键流程说明如下:
- 给 SDRAM 上电,并提供稳定的时钟,至少100us;
- 发送“空操作”(NOP)命令;
- 发送“预充电”命令,控制所有BANK进行预充电,并等待 tRP 的时间;
- 发送至少2个“自送刷新”命令,每个命令后需等待 tRC 时间;
- 发送“加载模式寄存器”命令,配置 SDRAM 的工作参数,等待 tMDR 时间;
- 初始化流程完毕,可以开始读写操作;
模式寄存器各位定义如下:
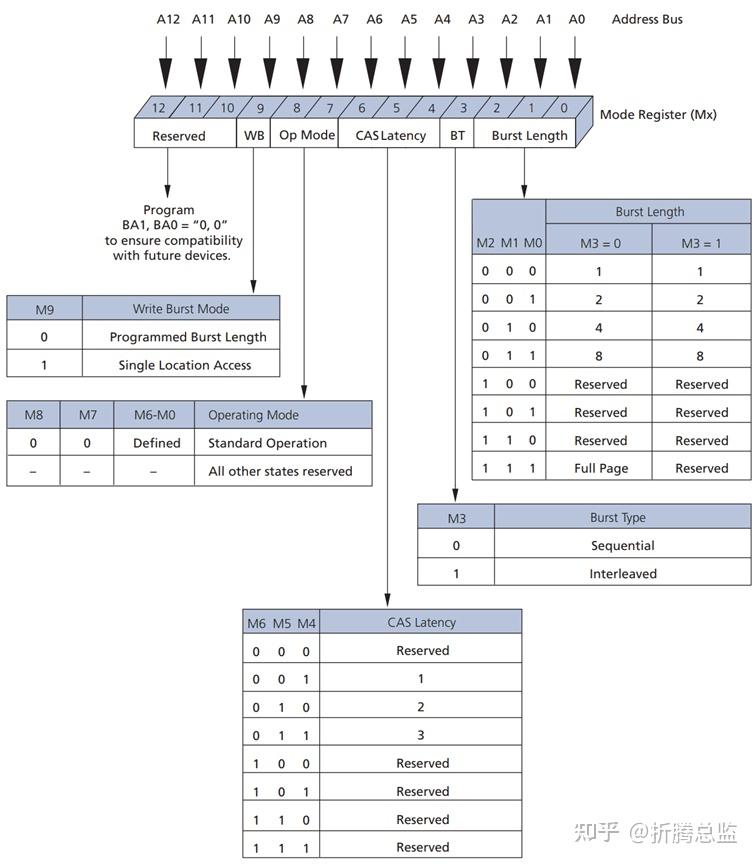
DDR 与预取技术
DDR 是 Double Data Rate (双倍数据速率)的简称,相比于 (SDR) SDRAM 仅在接口时钟的上升沿传输数据,DDR 在上升沿和下降沿都可以进行数据传输,所以总体运行频率没有变,但数据传输却快了一倍,如下图:
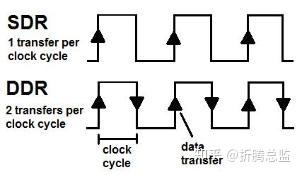
看似简单的解决方案,真正实现起来却不那么简单,主要有两个棘手的问题。
首先是双边沿触发的问题,它比单边沿对信号的要求更高。我们知道, SDRAM 信号是高频信号,随着 DDR 版本的迭代,对频率要求越来越高,而高频信号必然会遇到信号完整性问题,具体来说主要有以下这些问题:
- 信号传输线不均匀(如走线不合理、阻抗匹配不好)会造成信号的反射,让信号质量变差(如振铃),严重时会影响电平的判断;
- 无论怎么合理的走线,高频信号的上升沿不可避免会被拉缓,因为频率越高的信号,对于传输线的特性阻抗越敏感,阻抗大爬升自然就变缓;
- 信号线之间的时序问题,如时钟与地址/数据/控制线的长度不一致,会造成信号传输的时延不一致,可能产生误判。
上述所说的信号线,包括时钟、控制/地址、数据总线,而时钟是重中之重,因为它是驱动芯片工作和双方协同的关键。当 DRAM 还是单边沿触发时,还有较长的时间来让电平稳定后再采样,但当我们改为双边沿触发时,留给逻辑电路的时间至少少了一半。更为麻烦的是,因为时钟的上长沿被延缓,但下降沿基本没变,如下图上,造成了上升沿采样时间(T1)和下降沿采样时间(T2)不均等,更难与数据(DQ)的中心对齐,如下图:
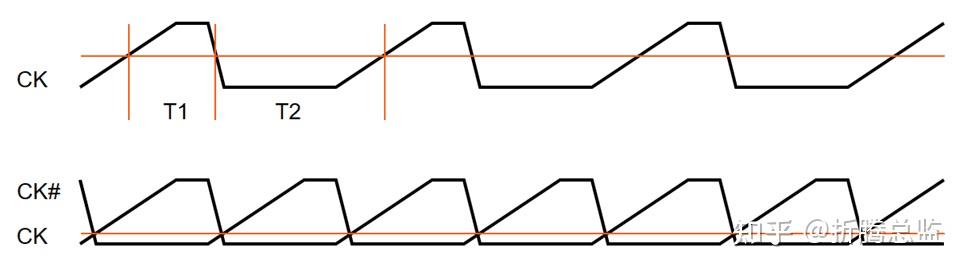
DDR 标准的解决方案是引入差分时钟。如图,差分时钟的交叉处,电压差为 0,以此作为采样触发条件,采样间隔终于均匀了。此外,差分时钟还有很多其它好处,如共模噪声(EMC、串扰、反射振铃等)将被抑制,作为 DRAM 的驱动时钟将更为稳健。同时,PCB 走线要求也变简单了,不用考虑参考平面的返回路径问题。
我们有了均匀的采样触发条件后,再考虑时序问题,具体来说是数据信号的对齐问题,即想办法在采样触发时,数据线上的电平已经稳定且离下一位的数据切换还有一定时间。在 SDR 时代是没有这个问题的,因为整个时钟周期都可以采样,接收端可以选择下降沿采样,刚好在 1 位数据的中间位置,即使时钟线与数据线长度有差别,出现时延,一般也能落在数据线的稳定电平区间。在 DDR 改为双边沿触发后,DRAM 控制器在写数据时,发送驱动电路必须为每一根数据线增加时延电路,延时 1/4 时钟周期,让 1 位的数据中心与时钟采样点对齐,以便让 DRAM 可以准确采样,如下图:
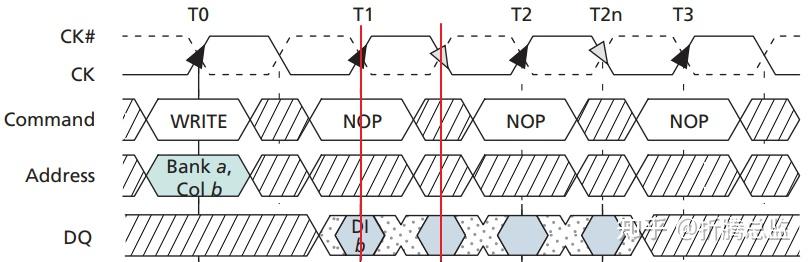
但 DRAM 控制器在处理读操作时,问题没有这么简单。在 DRAM 芯片端,不可能增加延时电路,这样成本开销太大,所以 DRAM 芯片只能按控制器给的时钟来同步发送数据,数据对齐的工作仍然交给控制器。问题是,控制器要把数据或解析时钟延时多久?注意时钟是由控制器产生并输出给 DRAM 的,因为传输线路有延时,DRAM 收到的时钟已经有时延了。然后 DRAM 发送数据参考的是这个时钟,数据总线还得有一次延时,控制器收到的数据时序,对于自身的时钟来说,相当于经过了两次延时。应该延时多少取决于时钟和数据线的走线长度(主板、内存条),每个应用都可能不一样。这可以让用户根据主板和内存条的走线来配置时延的长度,但用户显然没这么专业。更加糟糕的是,信号的延时还受环境(如温度)的影响,想配置也不好操作。
DDR 的解决方案增加一条数据解析专用的参考时钟线 DQS,一劳永逸解决了时序问题,并且应用电路的设计难度也降低了。原来的差分时钟仅用于控制和地址(CA)总线的同步采样,数据传输不再直接依赖时钟了,这意味着 PCB 布线时,只要求时钟与控制和地址总线等长即可,数据总线不用再等长。数据采样使用 DQS 信号即可,这意味着 DQS 要与数据总线等长。DQS 是双向信号,总是由发送端发出,接收端解析数据总线的时序就有了保障。
当控制器写数据到内存时,控制器把时钟信号直接作为 DQS 信号,与延时 1/4 周期的数据一起传输给 DRAM 芯片。因为它们的传输线是等长的,DRAM 就可以直接采用 DQS 的上升沿和下降沿来采样总线数据,如下图:
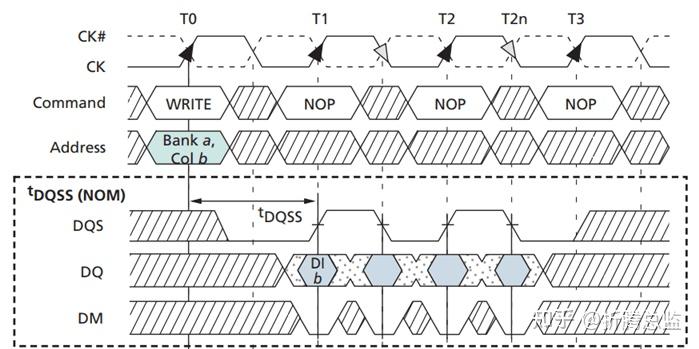
当控制器从内存读数据时,DRAM 把控制器给的时钟作为参考时钟,与数据一起传回给控制器,因为它们的传输线是等长的,之间没有时序差,控制器解析时,只需把 DQS 或数据延时 1/4 周期,即可准确的采样数据。
注意每 8 位数据总线配一根 DQS 信号,这样设计仍然是降低应用设计的 PCB 布线难度,因为控制器出来的数据总线会被分到不同的芯片,全部要求等长不好走线。
从 DDR2 时代开始,总线频率翻了一倍又一倍,对信号完整性的要求更高了,只能把 DQS 信号也变成了差分信号,如下图:
其次是数据速率不匹配问题。在双边沿传输后,数据传输率快了一倍,但是 DRAM 芯片内部的运行时钟还维挂接口时钟,芯片自身的读写速率明显比传输速率要慢一倍,读的没有传的快,不够传啊,怎么办?
为了适配 DDR 的翻倍速率,我们不得不引入了一个被称为预取(Prefetch)的新技术,其实这个技术也很简单,就是提前准备翻倍的数据放到寄存器中,让接口分两次拉完。假如一个 DRAM 芯片对外 DDR 接口的数据带宽是 4位 ,这意味着 一次(半个时钟周期)能传 4 位二进制数。那么,在芯片内部,就把数据带宽翻倍到 8 位,这样的话,CPU 发起的一次读写操作,在定位到具体的行列后,就会有8个读写电路同时工作,同时连通 8 条 Bitline(对),一次时钟就能同时读取 8 位数据并锁存到发送缓冲寄存器中,等待接口分两次把数据拉走,数据读写与传输速率终于匹配了。
大家有没有觉得 Prefetch 技术很牛X?其实一点也不牛,就只是稍微改变了一下存储阵列的组织结构,把内部数据带宽扩宽一倍而已(以DDR1为例)。具体来说,就是把芯片的读写驱动电路翻倍,然后把 2 倍的 CSL 信号并联在一起,这样的话,一条 CSL 就能选中翻倍的 Bitline 线对,连通到翻倍个读写驱动电路,实现同时读取翻倍的信息。如果大家还有疑惑,可以回到存储阵列一节仔细研读。
从 Prefetch 原理可以看出,Prefetch 增加的晶体管数量很少(因为要增加的读写驱动电路是复用的),设计复杂度没有增加,而增加的成本微乎其微,好处却是大大的有:传输速率翻倍了,但内部时钟频率一点也不用提升。为什么 DRAM 行业那么害怕提高频率?因为有牛逼洪洪的 RDRAM 内存做教训啊,Rambus 冒进大幅提升核心频率上,但短期内芯片厂商的工艺又上不去,致使芯片的发热量大幅上升,进而影响芯片的生产良率和运行可靠性,致使价格大幅提升,性能和稳定性还不及预期。大家可以想想,一片小小的芯片,内部堆了那么多晶体管,外部又没有像 CPU 那样强悍的散热系统,能不爆么?
所以大家也看到了,后来的 DDR 标准一再祭出 Prefetch 大法,预取的数据越来越多,内部总线越来越宽,无它,好用啊。
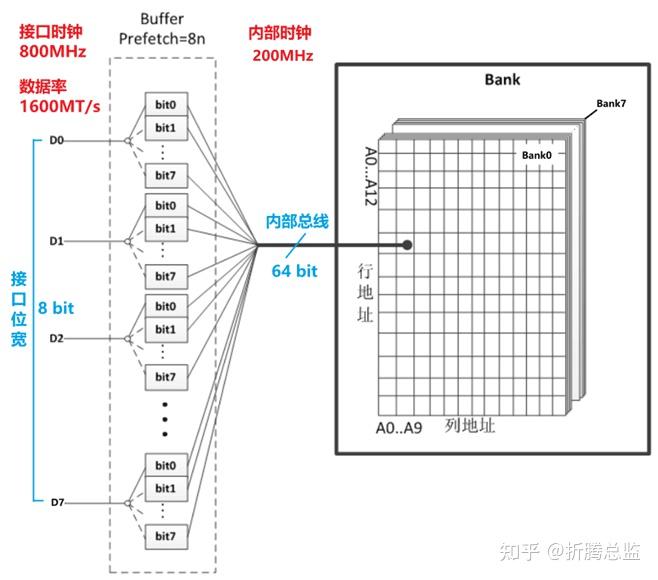
从 SDR 到 DDR3,DDR 芯片的核心频率一直维持在 100-266MHz 之间,起步频率都是 100MHz,提升数据率全靠预取技术,Prefetch 从 DDR 的 2 倍持续提升到 DDR3 的 8 倍,这意味着 DDR3 芯片内部的数据总线是 DDR 接口位宽的 8 倍,如一个 8 位的 DDR3 芯片,内部数据总线是 64 位,一次行列选择操作能同时选中 64 个 Cell,驱动 64 个读写电路同时工作,完成 64位数据的读写。读出的 64 位数据被锁存在 8 个 8 位的 FIFO 缓冲队列中,靠 4 倍于内核时钟的高速接口时钟,分 8 个上升下降沿传输完成,如下图:
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 351134995@qq.com

